配置系统
ParseOption:解析配置的类
XXOption:这些都是各个类的配置.
使用:XXOption中都包含一个Register(ParseOption &itf)方法,该方法直接把该类中的Option中的变量注册到ParseOption中{注册使用的全是引用,目的就是通过ParseOption的接口来设置XXOption中的变量},然后使用ParseOption的读写方法操作配置文件、以及解析配置文件.
MFCC
MfccComputer、PlpComputer、FbankComputer:实际计算feature的类
offline特征提取:
template
OfflineFeatureTpl:特征计算的包装,F{MfccComputer,xxx},其中包含语音的处理,feature_window_function_都在该类中,ExtractWindow,PorcessWindows等.也就是说用户应该使用这个类,而不应该直接使用MfccComputer.
Online的特征提取:
feat/online-feature.h:129
ypedef OnlineGenericBaseFeature
typedef OnlineGenericBaseFeature
typedef OnlineGenericBaseFeature
具体的提取特征的动作还是用的MfccComputer等,其他的设置、处理等都是在OnineGenericBaseFeaure模版中处理.
熵
简单来说,熵是表示物质系统状态的一种度量,用它表征系统的无序程度.熵越大,越无序.
最大熵模型
在学习概率模型时,所有可能的模型中熵最大的模型是最好的模型;若概率模型需要满足一些约束,则最大熵原理就是在满足已知约束的条件集合中选择熵最大模型。最大熵原理指出,对一个随机事件的概率分布进行预测时,预测应当满足全部已知的约束,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小,因此得到的概率分布的熵是最大。
说白了就是:最大熵描述的是这样一个自然事实,即基于当前已知前提下,也就是约束下,未知事件的概率尽可能的接近最符合事物的自然规律。
HMM
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
是在被建模的系统被认为是一个马尔可夫过程与未观测到的(隐藏的)的状态的统计马尔可夫模型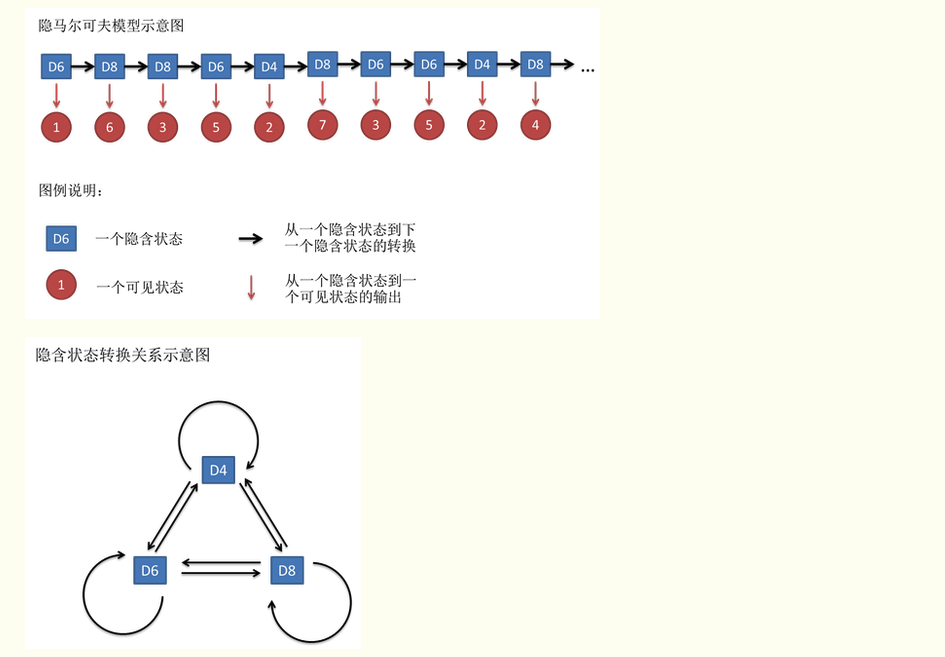
HMM的三个基本问题:
例如:问题3训练模型,问题1评估模型(主要是评价得到的模型是否可靠),问题2使用训练好的模型求解在观测序列下概率最大的隐含序列(语音识别)
声学模型(GMM-HMM)
在GMM-HMM模型中常用的语音特征是MFCC
声学模型的目的是将经MFCC提取的所有帧的特征响亮转化为有序的音素输出.
hmm隐含状态和一个音素之间的关系
通常一个音素会由多个状态构成,而一个状态通常会有多个语音帧,而在GMM-HMM模型中,我们是对帧做的GMM如下图所示: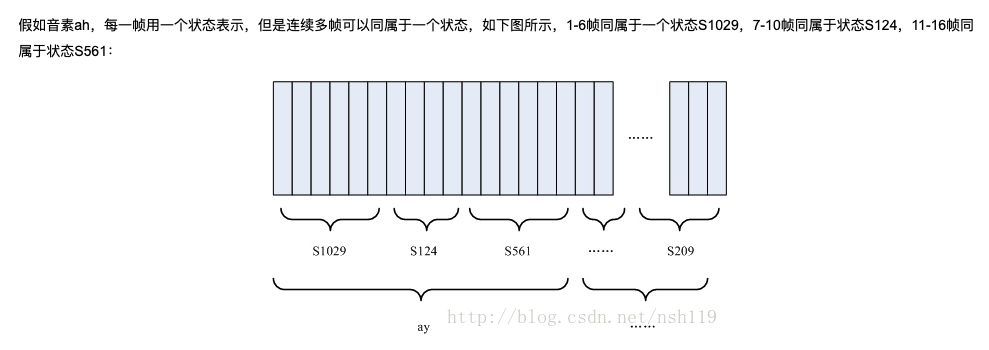
GMM的作用:GMM主要是为了得到HMM求解过程的发射概率
HMM的作用:就是根据各个概率得到最优的音素,单词以及橘子序列.(HMM的三个问题中的第二个解码问题)
语音HMM模型图示: